I would like to thank Hans, Luigi, and other researchers for some conversations on ideas in this post.
As research hands off coordicide to the engineers, we are now free to take a closer look at the next step in the evolution of Iota: sharding. We have already began discussing how to dynamical or fluid sharding which automatically adjust the number of shards to meet the current congestion requirements of the network and to allow true infinite scalability.
However, as I discussed in here, I think dynamic sharding is a tough problem. By tough, I do not mean impossible (I am very optimistic about our work so far), but I think it will take awhile to figure everything out. However, there are some easier “data sharding” possibilities which give us more mileage from Iota 2.0 which might really benefit our community and could be stop gap till we devise a full sharding solution.
With this post, I would like to begin a conversation in the Iota foundation and in the community about finding a vision for sharding that best services the community’s needs and can be realized as quickly as possible. At the end of the day I am just a mathematician and I usually study what is possible and what is not. In this case though, I would like some people to tell me what is needed.
Introduction
A DLT is a state machine: it keeps a ledger of balances and records changes to these balances. A DLT also has a consensus mechanism that protects the state from tampering. The security of a DLT relies on an honest majority enforcing the protocol and using the consensus mechanism.
In a sharded DLT, we create a set of state machines whose states are all inter connected. Each machine is run and secured by a fraction of the network. As a result, nodes do not need to process all the transactions in the network.
Roughly speaking, the key problem in sharding is securing each shard: with only a fraction of the network protecting a shard, it is more vulnerable. Moreover if one shard breaks, then all shards are compromised, and thus securing each shard is absolutely critical.
Data however is far less problematic: data messages or zero value transactions do not affect the ledger state. Thus, they can not be used to “break” the ledger. Thus, philosophically, creating shards that only deal with data are far less problematic! Data sharding exploits this possibility by requiring all nodes to process all “ledger mutating” transactions, but allowing nodes to choose what data they process.
Compression
The first and easiest data sharding technique is compression. Amongst other things, a hash function can compress an arbitrary amount of data into a hash. We can research methods of creating and optimizing second layer solutions which use the compression function.
Suppose I am a weather sensor. I can measure gigabytes of data’s worth of data, create a merkle tree and then publish the root once a day on the tangle. If anyone ever asks me for the temperature at 12:00 on a particular day, I can provide them with the information and a merkle proof. If they only record the merkle roots each day, they can verify my findings.
The weather sensor’s information is secured by the DLT, even though most node will not need to process the data its storing.
Unfortunately, this approach has limits. The other data stored in the merkle tree is secret unless the sensor reveals it. Suppose I want to verify that it has not rained for a month. Unless the sensor provides me the entire tree, it maybe hiding a rain measurement from me.
What are the exact limits of this technique? What kind of uses cases can it service? Can we tweak it to make it more powerful?
Side Data Networks
The current cooridice solution runs on mana: any application requiring sybil protection system uses mana. For instance autopeering, rate control, DRNG, and FPC all use the function getMana whose input is a node ID and whose output is an integer. These application govern what data is added to the tangle, which determines the ledger state. Mana is then calculated from the ledger.
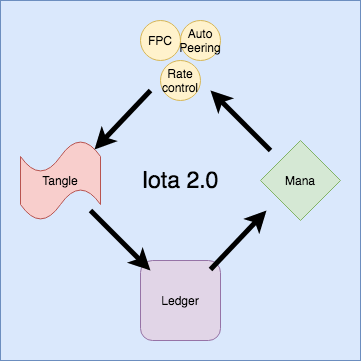
As depicted in this diagram, we get a cyclical cycle that is continuously updating. In order to compute mana, a node must track the entire network.
I propose that we use the autopeering algorithm and the rate control mechanism to create a separate side network with a side tangle. However ,mana in the main network would provide the sybil protection mechanism for these modules in the side network. Moreover, this side network would not contain value objects or transactions: only data.

Every node would need to process the main iota network in order to correctly compute the mana vector, however different nodes could choose whether or not to follow the side network
In fact, many of these side networks can be created, and each node could choose which ones to follow (as long as they follow the main network too). Moreover, parameters like bandwidth usage etc can be adjusted to the needs of each individual network. The IF could create software enabling anybody to set up a side network.
The “security” of each side network will be provided the scarceness of mana. Also, it seems possible to use colored coins to create “colored mana” which can be used in a specific network.
Unfortunately, each side network might not be completely secure. The sum of mana held by nodes in the side network could be far less than in the main network. If an attacker has enough mana, they could attack the autopeering and rate control modules. Although, without a consensus mechanism, the attack would be limited in score. Moreover, since these side networks wont affect the main network, this is only a local problem: users can choose which side networks to trust their data in.
Lastly, we could attempt to create some sort of dynamical data sharding side network that combines the continuous sharding we have discussed earlier. This could create an indefinitely scalable network that is
Side state machines
The side networks previous discussed could also support separate state machines besides the ledger such as smart contracts.
As mentioned earlier, FPC operates only using a sybil protection system like mana. Thus FPC could to vote on objects in another network using the mana from the main network. In fact, the side tangle could any consensus algorithm that uses the mana.
What would we vote on in this side tangle?
Next, I would like to explain the concept of zero value UTXOs. In a UTXO scheme, a transaction has several inputs and several outputs. Theoretically, the funds moved by each of these inputs and out puts could be 0. Why would we do this? The network still votes on the consumption of UTXOs: no two transactions can consume the same inputs. Thus these transactions still define well defined actions on state machines, and thus can support certain applications and execute certain smart contracts.
Here is an example. Suppose I build a house which I identify with a unique House ID. Now suppose that I sell it this house to a person with the public key A (aka an address). With 0 value UTXOs, then I can issue a transaction on the tangle which lists the House ID and has one 0 balance output controlled by A.

This certifies the creation of the house and its ownership. It is a valid transaction because the sum of input iotas equals the sum of the output iotas: 0.
Now suppose A sells the house to public key B. Then A issues a transaction listing the house ID, consumes Output 1, and produces an output controlled by B.
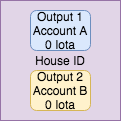
Since this transaction moves no iotas and outputs no iotas, this transaction is valid. Since only one transaction can consume Output 1, B will be the undisputed owner of the house.
In this example, the UTXO scheme defines an action on the state machine “who owns the house”. However, this machine is completely separate from the ledger.
A side tangle equipped with a consensus mechanism can also support 0 value UTXOs. In fact, the only transactions it could contain would be 0 value, so this side tangle again could not move any iota. However, it could support applications like that described above. This set up is strong enough to have some smart contract functionality.

Again, as discussed in the previous section, the scarcity of mana will help secure these consensus algorithms, however security would not be guaranteed for small side tangles with little traffic. But since these side tangles cannot move funds, the security questions are only local.
The future of sharding
Before the research department begins considering sharding, I think its imperative that we define the scope of our project and make sure that our research effectively services the community’s needs. The primary point of this post is not to discuss these data sharding ideas per se, but to demonstrate that our sharding research can actually take several paths.
Secondly, I ask the following questions: is data sharding potentially useful? Should the IF invest resources into developing these ideas?
If Iota is fully adopted, then the 1000 tps goal of coordicide will not suffice even with data sharding. However, this level of adoption will not happen overnight, and data sharding could be sufficiently scalable to out perform our competitors.